July 31, 2023
Hao Phung, Quan Dao, Anh Tran
Along with the outbreak of the pandemic, information about the COVID-19 is aggregated rapidly through different types of texts in different languages. Particularly, in Vietnam, text reports containing official information from the government about COVID-19 cases are presented in great detail, including de-identified personal information, travel history, as well as information of people who come into contact with the cases. The reports are frequently kept up to date at reputable online news sources, playing a significant role to help the country combat the pandemic. It is thus essential to building systems to retrieve and condense information from those official sources so that related people and organizations can promptly grasp the key information for epidemic prevention tasks, and the systems should also be able to adapt and sync quickly with epidemics that take place in the future. One of the first steps to develop such systems is to recognize relevant named entities mentioned in the texts, which is also known as the named entity recognition (NER) task.
Compared to other languages, data resources for the Vietnamese NER task are limited, including only two public datasets from the VLSP 2016 and 2018 NER shared tasks. These two datasets only focus on recognizing generic entities of person names, organizations, and locations in online news articles. Thus, making them difficult to adapt to the context of extracting key entity information related to COVID-19 patients.
These two concerns lead to our work’s main goals that are:
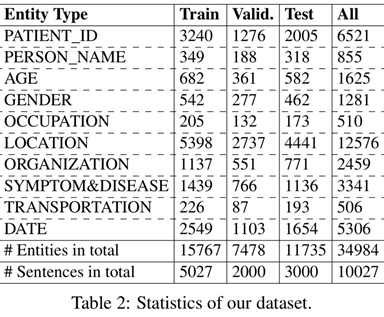
We define 10 entity types to extract key information related to COVID-19 patients, which are especially useful in downstream applications. In general, these entity types can be used in the context of not only the COVID-19 pandemic but also in other future epidemics. The description of each entity type is briefly described in Table 1.

In summary, our dataset construction consists of the following phases:
We conduct experiments on our dataset using strong baselines including: BiLSTM-CNN-CRF (denoted as BiL-CRF) and the pre-trained language models XLM-R and PhoBERT. XLM-R is a multi-lingual variant of RoBERTa, pre-trained on a 2.5TB multilingual dataset that contains 137GB of syllable-level Vietnamese texts. PhoBERT is a monolingual variant of RoBERTa, pre-trained on a 20GB word-level Vietnamese dataset. Our main findings are:
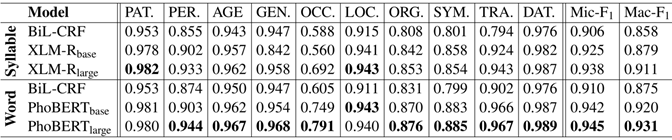
We presented the first manually-annotated Vietnamese dataset in the COVID-19 domain, focusing on the named entity recognition task. We empirically conduct experiments on our dataset to compare strong baselines and find that the input representations and the pre-trained language models all have influences on this COVID-19 related NER task. We publicly release our dataset and hope that it can serve as the starting point for further Vietnamese NLP research and applications in fighting the COVID-19 and other future epidemics.
See our NAACL 2021 paper for details of the dataset construction and experimental results: https://arxiv.org/abs/2104.03879
Our dataset is publicly released: https://github.com/VinAIResearch/PhoNER_COVID19
Overall
Thinh Hung Truong, Mai Hoang Dao, Dat Quoc Nguyen
Share Article

Hao Phung, Quan Dao, Anh Tran

Khai Nguyen (*), Dang Nguyen (*), Nhat Ho

Hoang Phan, Trung Le, Trung Phung, Tuan Anh Bui, Nhat Ho, Dinh Phung

Tuan Duc Ngo, Binh-Son Hua, Khoi Nguyen