July 11, 2023
Linh The Nguyen, Thinh Pham, Dat Quoc Nguyen
Vietnam has achieved rapid economic growth in the last two decades. It is now an attractive destination for trade and investment. Due to the language barrier, foreigners usually rely on automatic machine translation (MT) systems to translate Vietnamese texts into their native language or another language they are familiar with, e.g. the global language English, so they could quickly catch up with ongoing events in Vietnam. Thus the demand for high-quality Vietnamese-English MT has rapidly increased. However, state-of-the-art MT models require high-quality and large-scale corpora for training to be able to reach near human-level translation quality. Despite being one of the most spoken languages in the world with about 100M speakers, Vietnamese is referred to as a low-resource language in MT research because publicly available parallel corpora for Vietnamese in general and in particular for Vietnamese-English MT are not large enough or have low-quality translation pairs, including those with different sentence meanings (i.e. misalignment).
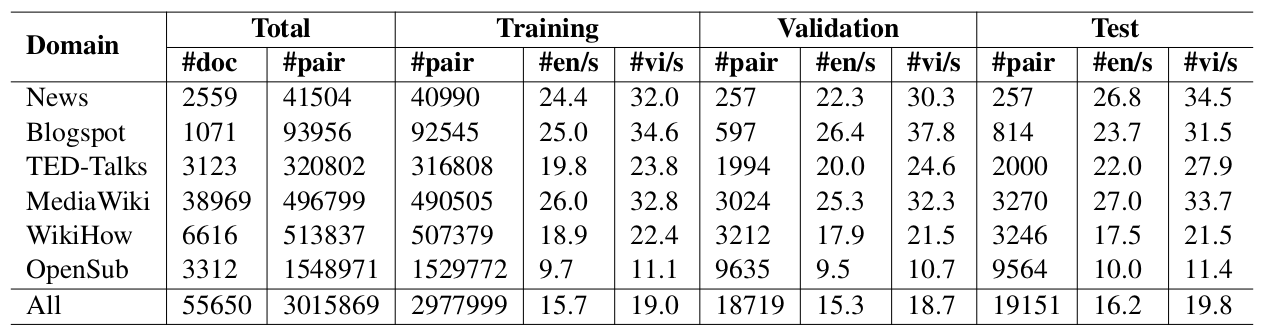
Our dataset construction process consists of 4 phases.
Our main goals are to:
We find that:
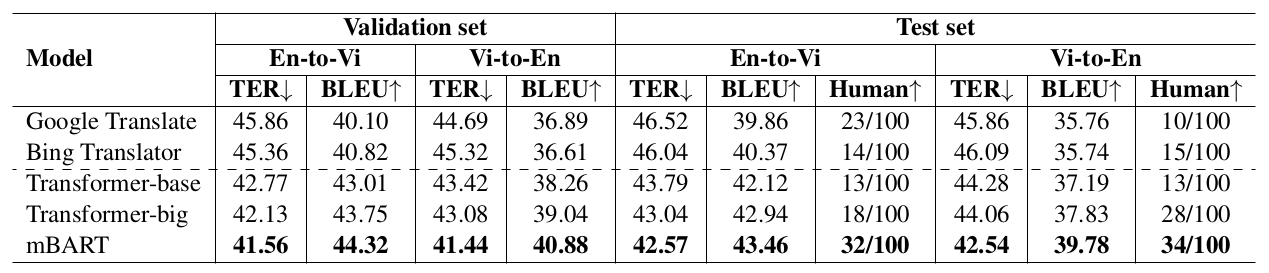
We have presented PhoMT—a high-quality and large-scale Vietnamese-English parallel dataset of 3.02M sentence pairs. We empirically conduct experiments on our PhoMT dataset to compare strong baselines and demonstrate the effectiveness of the pre-trained denoising auto-encoder mBART for neural MT in both automatic and human evaluations. We hope that the public release of our dataset can serve as the starting point for further Vietnamese-English MT research and applications.
See our EMNLP 2021 paper for details of the dataset construction and experimental results: https://arxiv.org/abs/2110.12199
Our dataset is publicly released: https://github.com/VinAIResearch/PhoMT
Overall
Long Doan, Linh The Nguyen, Nguyen Luong Tran, Thai Hoang, Dat Quoc Nguyen
Share Article

Linh The Nguyen, Thinh Pham, Dat Quoc Nguyen

Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen

Dang Minh Nguyen, Anh Tuan Luu

Linh The Nguyen*, Nguyen Luong Tran*, Long Doan*, Manh Luong and Dat Quoc Nguyen