July 11, 2023
Linh The Nguyen, Thinh Pham, Dat Quoc Nguyen
Speech translation – the task of translating speech in one language typically to text in another – has attracted interest for many years. However, the development of speech translation systems has been largely limited to high-resource language pairs because most publicly available datasets for speech translation are exclusively for the high-resource languages. From a societal, linguistic, machine learning, cultural and cognitive perspective, it is also worth investigating the speech translation task for low-resource languages, e.g. Vietnamese with about 100M speakers. Vietnam is now an attractive destination for trade, investment and tourism. Thus the demand for high-quality speech translation from the global language English to Vietnamese has rapidly increased.
To our best knowledge, there is no existing research work that focuses solely on speech translation to Vietnamese. The only available resource for speech translation to Vietnamese is the 441-hour English-Vietnamese speech translation data from the TED-talk-based multilingual dataset MuST-C. We manually inspect both the validation set and the test set from the MuST-C English-Vietnamese data. Here, each triplet is checked by two out of our first three authors independently. After cross-checking, we find that: 5.63% of the validation set and 4.10% of the test set have an incorrect audio start or end timestamp of an English source sentence; 16.15% of the validation set and 9.36% of the test set have misaligned English-Vietnamese sentence pairs (i.e. completely different sentence meaning or partly preserving the meaning). As the training/validation/test split is random, the substantial rates of incorrect timestamps and misalignment on the validation and test sets imply that the MuST-C English-Vietnamese training set might also not reach a high-quality level.
To handle the concerns mentioned above, we introduce PhoST–a high-quality and large-scale English-Vietnamese speech translation dataset containing 508 audio hours. We construct PhoST through five phases:
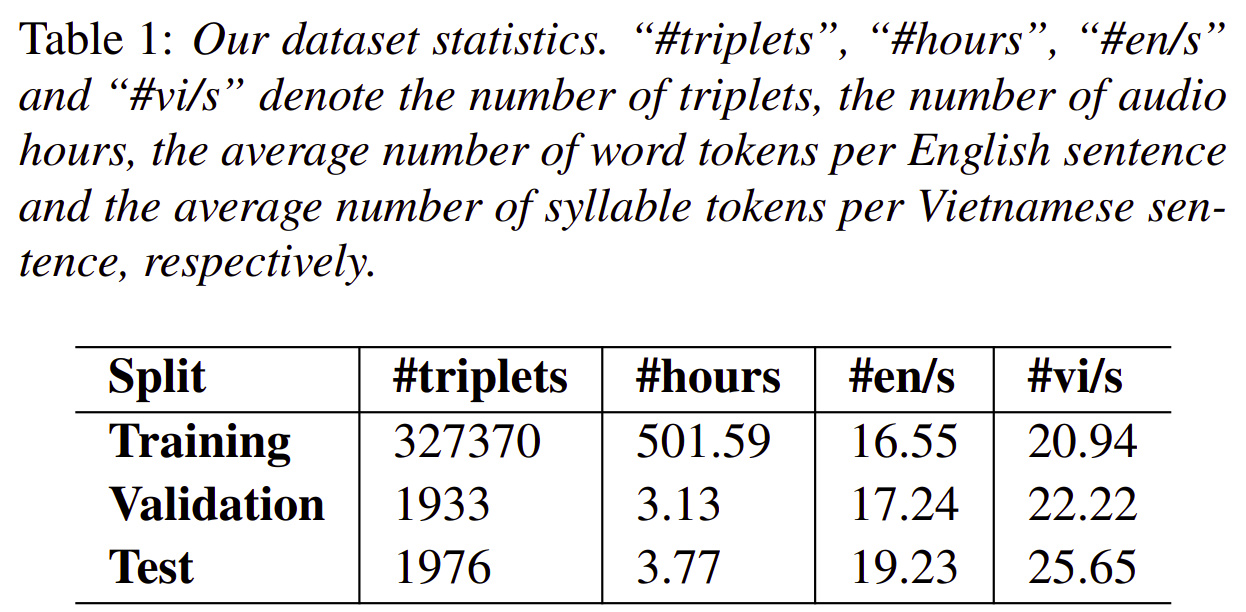
Table 1 shows the statistics of our PhoST dataset.
On our PhoST dataset, we compare two speech translation approaches: “Cascaded” vs. “End-to-End”.
The “Cascaded” approach combines two main components of English automatic speech recognition (ASR) and English-to-Vietnamese machine translation (MT). For ASR, we train the Fairseq’s S2T Transformer model on our English audio-transcript training data. For MT, we fine-tune the pre-trained sequence-to-sequence model mBART that obtains the state-of-the-art performance for English-Vietnamese machine translation. We also perform data augmentation to extend the MT training data.
For the “End-to-End” approach that directly translates English speech into Vietnamese text, we study two baselines, including the S2T Transformer model and the UPC’s speech translation system Adaptor which is the only top performance system at IWSLT 2021 with publicly available implementation at the time of our empirical investigation.
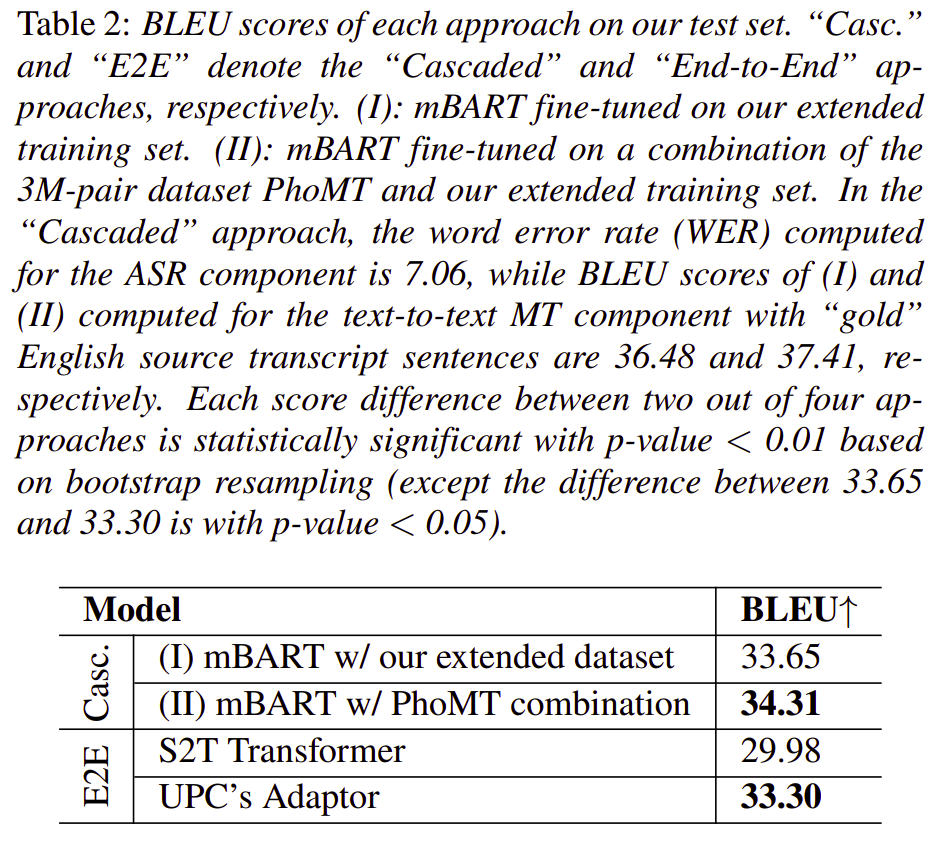
Table 2 presents the final BLEU score results obtained by each speech translation approach on our test set. For “Cascaded” results, with the same automatic ASR output as the model input, it is not surprising that fine-tuning mBART on a combination of PhoMT and our extended training set helps produce a better BLEU score than fine-tuning mBART on only our extended training set (34.31 vs. 33.65), thus showing the effectiveness of a larger training size. For “End-to-End” results, it is also not surprising that with the ability to leverage strong pre-trained models Wav2Vec2 for ASR and mBART for machine translation, the UPC’s Adaptor system obtains a 3+ absolute higher BLEU score than the S2T Transformer model trained solely without pre-training (33.30 vs. 29.98). In a comparison between the “Cascaded” and “End-to-End” results, we find that the “Cascaded” approach does better than the “End-to-End” approach.
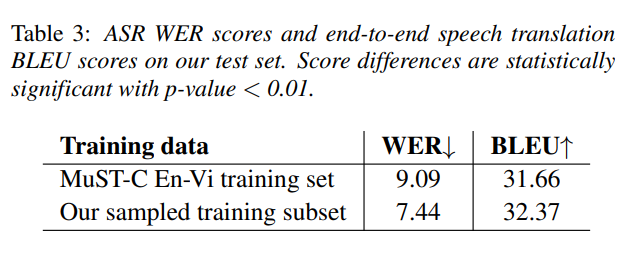
To further investigate the impact of our curation effort, we also conduct experiments comparing model performances on the MuST-C English-Vietnamese (En-Vi) training set and our training set. For a fair comparison, as not all of our data are overlapping with MuST-C, we filter from the MuST-C En-Vi training set all TED talks that appear in our validation and test sets. We then sample a subset of TED talks from our training set so that our sampled subset has the same total number of speech hours as the filtered MuST-C En-Vi training set. We first train two S2T Transformer models for ASR and then two end-to-end Adaptor models for speech translation, using our sampled subset and the filtered MuST-C En-Vi training set. We evaluate these models using our test set and report obtained results in Table 3. On the ASR task, the S2T Transformer trained using our sampled subset obtains a lower WER than the S2T Transformer trained using the MuST-C data (7.44 vs. 9.09), showing our better audio-transcript alignment. Similarly, on the speech translation task, the end-to-end Adaptor model trained using our sampled subset does better than the one trained using the MuST-C data (32.37 vs. 31.66), demonstrating the effectiveness of our curation effort w.r.t. the end-to-end setting.
We have introduced PhoST–a high-quality and large-scale dataset with 508 audio hours for English-Vietnamese speech translation. On PhoST, we empirically conduct experiments using strong baselines to compare the “Cascaded” and “End-to-End” approaches. Experimental results show that the “Cascaded” approach does better than the “End-to-End” approach. We hope that this work helps accelerate research and applications on English-Vietnamese speech translation.
Read the PhoST paper: https://www.isca-speech.org/archive/pdfs/interspeech_2022/nguyen22_interspeech.pdf
The PhoST dataset is publicly released at: https://github.com/VinAIResearch/PhoST
Overall
Linh The Nguyen*, Nguyen Luong Tran*, Long Doan*, Manh Luong and Dat Quoc Nguyen
Share Article

Linh The Nguyen, Thinh Pham, Dat Quoc Nguyen

Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen

Dang Minh Nguyen, Anh Tuan Luu
