July 31, 2023
Hao Phung, Quan Dao, Anh Tran
Understanding events entails recognizing the structural and temporal orders between event mentions building event structures/ graphs for input documents. To achieve this goal, our work addresses the problems of subevent relation extraction (SRE) and temporal event relation extraction (TRE) that aim to predict subevent and temporal relations between two given event mentions/triggers in texts (event-event relation extraction problems – EERE).
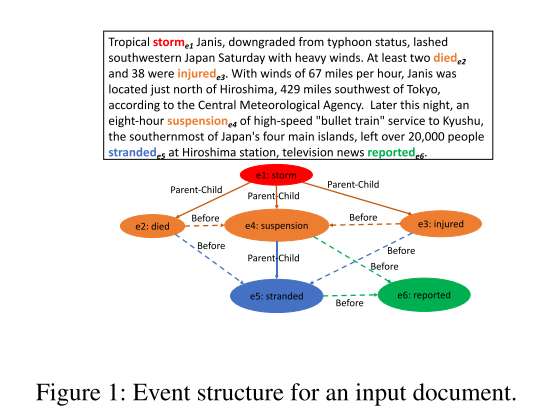
Recent state-of-the-art methods for such problems have employed transformer-based language models (e.g., BERT (Devlin et al. 2019)) to induce effective contextual representations for input event mention pairs. However, a major limitation of existing transformer-based models for SRE and TRE is that they can only encode input texts of limited length (i.e., up to 512 sub-tokens in BERT), thus unable to effectively capture important context sentences that are farther away in the documents.
Therefore, in this work, we introduce a novel method to better model document-level context with important context sentences for event-event relation extraction. Our method seeks to identify the most important context sentences for a given entity mention pair in a document and pack them into shorter documents to be consumed entirely by transformer-based language models for representation learning.
Self-Attention Architecture Modification (Zaheer et al. 2020; Beltagy, Peters, and Cohan 2020; Kitaev, Kaiser, and Levskaya 2020): Replace the vanilla self-attention of transformer networks with some variant architectures, e.g., sparse self-attention (Zaheer et al. 2020), that allows the modeling of larger document context while maintaining the same complexity as the original transformer
Hierarchical Designs (Adhikari et al. 2019; J¨orke et al. 2020): the standard transformer-based language models are still leveraged to encode input texts with certain length limits. For larger input documents, another network architecture will be introduced to facilitate representation induction.
Drawbacks:
To address these issues, we propose to design models that can learn to select important context sentences for EERE to improve representation learning with BERT.
In particular, starting with the host sentences of the two event mentions of interest, we will perform the sentence selection sequentially. The total length of the selected sentences will be constrained to not exceed the input limit in transformer-based models, thus allowing the entire consumption and encoding of the models for the selected context. To train this model, the policy-gradient method REINFORCE (Williams 1992) is leveraged which is guided by three rewards:
The goal of this section is to select the most important context sentences C for the event relation prediction between e1 and e2 in D. A sentence Sk ∈ D is considered to involve important context information for EERE if including Sk into the compressed document D’ can lead to improved performance for the prediction model over e1 and e2.
Our sentence selection model follows an iterative process where a sentence in Scontext is chosen at each time step to be included in the sentence set C. In particular, C is empty at the beginning (step 0). At step t + 1 (t ≥ 0), given t sentences selected in previous steps, i.e., C we aim to choose a next sentence Sk t+1 over the set of non-selected sentences
Stcontext = Scontext C
To summarize the selected sentences in prior steps, we run a Long Sort-Term Memory Network (LSTM) over the representation vectors xk i of the selected sentences. The hidden vector ht of LSTM at step t will serve as the summarization vector of the previously selected sentences. Afterward, the selection of Sk t+1 at step t+1 will be conditioned on the selected sentences in prior steps via their summarization vector ht. In particular, for each non-selected sentence Su ∈ Stcontext, a selection score scut+1 is computed as a function of the representation vector xu of Su in X and the summarization vector ht:
scut+1 = sigmoid (G[xu, ht])
where G is a two-layer feed-forward network.
To this end, the sentence Su* with highest selection score, i.e., Su* = argmax scut+1, will be considered for selection at this step.
We utilize the REINFORCE algorithm (Williams 1992) that can treat the prediction performance as the reward function R(C) for the selected sentence sequence C to train the selection processes for input documents. In addition, another benefit of REINFORCE involves its flexibility that facilitates the incorporation of different information sources from C to enrich the reward function R(C) and provide more training signals for the selection model. As such, for EERE problems, we propose the following information sources to compute the reward function R(C) for REINFORCE training:
The overall reward function R(C) to train our context selection module with REINFORCE for EERE is:
R(C) = αperRper(C) + αcontextRcontext(C) + αknowRknow(C)
We evaluate our model on four datasets: HiEve (Glavaˇs et al. 2014), MATRES (Ning, Wu, and Roth 2018), TDDMan and TDDAuto datasets in the TDDiscourse corpus (Naik, Breitfeller, and Rose 2019).
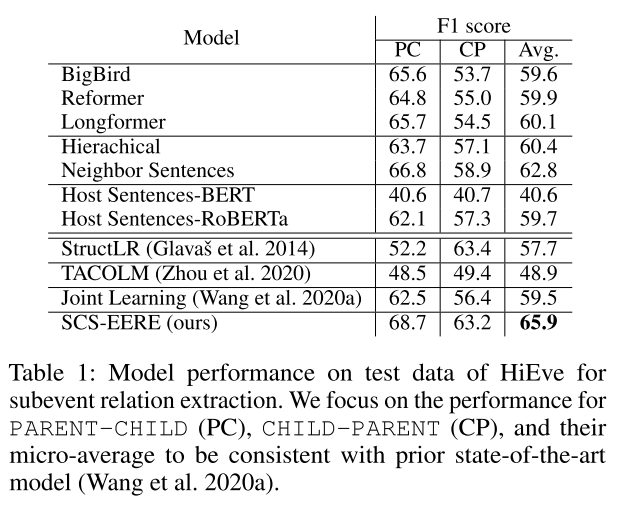
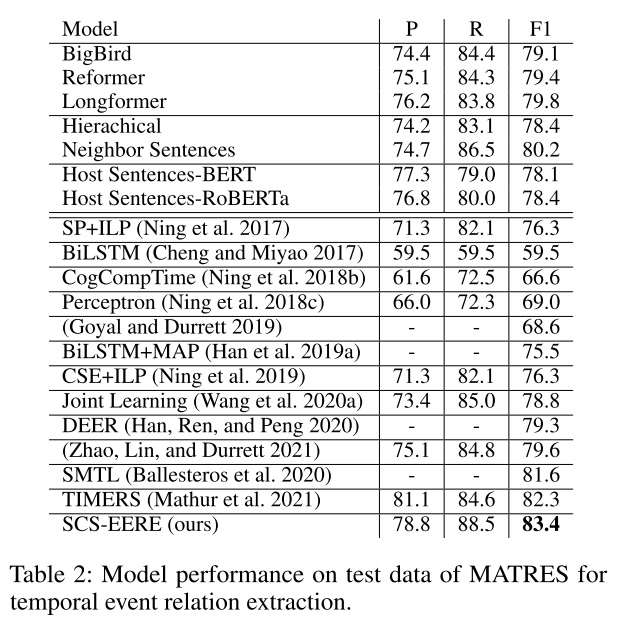
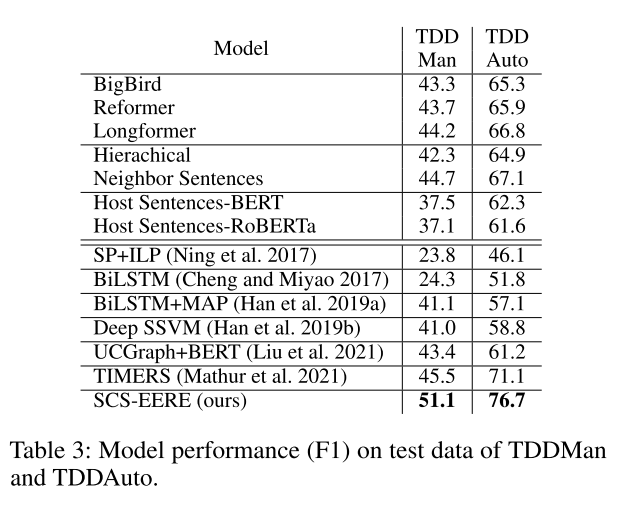
We found that our proposed method achieves significantly better performance in all four datasets.
We present a novel model for event-event relation extraction that learns to select the most important context sentences in a document and directly use them to induce representation vectors with transformer-based language models. Relevant context sentences are selected sequentially in our model that is conditioned on the summarization vector for the previously selected sentences in the sequence. We propose three novel reward functions to train our model with REINFORCE. Our extensive experiments show that the proposed model can select important context sentences that are far away from the given event mentions and achieve state-of-the-art performance for subevent and temporal event relation extraction. In the future, we plan to extend our proposed method to other related tasks in event structure understanding (e.g., for the joint event and event-event relation extraction).
Overall
Hieu Man Duc Trong (Research Resident)
Share Article

Hao Phung, Quan Dao, Anh Tran

Khai Nguyen (*), Dang Nguyen (*), Nhat Ho

Hoang Phan, Trung Le, Trung Phung, Tuan Anh Bui, Nhat Ho, Dinh Phung

Tuan Duc Ngo, Binh-Son Hua, Khoi Nguyen