July 25, 2023
Hoang Phan, Trung Le, Trung Phung, Tuan Anh Bui, Nhat Ho, Dinh Phung
Based on the closed-form solution of Wasserstein distance in one dimension, Sliced Wasserstein (SW) has been utilized successfully in point-cloud representation learning [1, 2] due to its computational efficiency. However, the downside of SW is that it treats all projections the same due to the usage of a uniform distribution over projecting directions. Thus, max sliced Wasserstein (Max-SW) [3] distance was proposed as a solution for less discriminative projections of sliced Wasserstein (SW) distance. In applications that have various independent pairs of probability measures, amortized projection optimization [4] was introduced to predict the “max” projecting directions given two input measures instead of using projected gradient ascent multiple times. Despite being efficient, Max-SW and its amortized version cannot guarantee metricity property due to the sub-optimality of the projected gradient ascent and the amortization gap. Therefore, in this paper, we propose to replace Max-SW with distributional sliced Wasserstein distance with von Mises-Fisher (vMF) projecting distribution (v-DSW). Since v-DSW is a metric with any non-degenerate vMF distribution, its amortized version can guarantee the metricity when performing amortization. Furthermore, current amortized models are not permutation invariant and symmetric, thus they are not suitable to deal with set-based data (e.g. point-clouds). To address the issue, we design amortized models based on self-attention architecture. In particular, we adopt efficient self-attention architectures to make the computation linear in the number of supports. With the two improvements, we derive self-attention amortized distributional projection optimization and show its appealing performance in point-cloud reconstruction and its downstream applications.
We denote a point-cloud of  points
points  (
( ) as
) as  which is a vector of a concatenation of all points in the point-cloud. We denote the set of all possible point-clouds as
which is a vector of a concatenation of all points in the point-cloud. We denote the set of all possible point-clouds as  . In the point-cloud representation learning, we want to estimate
. In the point-cloud representation learning, we want to estimate  (
( ) jointly with a function
) jointly with a function  (
( ) given a point-cloud dataset
) given a point-cloud dataset  (distribution over set of poin-clouds
(distribution over set of poin-clouds  ) by minimizing the objective:
) by minimizing the objective:
(1) 
Here,  is a metric between two point-clouds.
is a metric between two point-clouds.
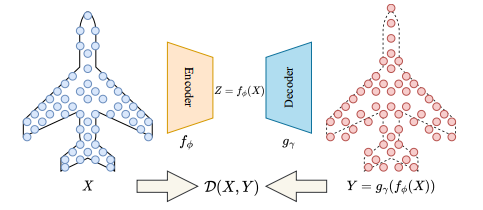
Figure 1. Overview of Point-cloud Reconstruction.
Max sliced Wasserstein (Max-SW) distance between  and
and  is:
is:
(2) 
where the Wasserstein distance has a closed form on one dimension which is
(3) 
with  and
and  are the inverse CDF of
are the inverse CDF of  and
and  respectively.
respectively.
Max sliced point-cloud reconstruction: Instead of solving all optimization problems independently, an amortized model is trained to predict optimal solutions to all problems. Given a parametric function  (
( ), the amortized objective is:
), the amortized objective is:
(4) ![\begin{equation*} \min_{\phi \in \Phi,\gamma \in \Gamma }\mathbb{E} \left[\max_{\theta \in \mathbb{S}^{d-1}}W_p(\theta \sharp P_X,\theta \sharp P_{g_\gamma (f_\phi(X))})\right], \end{equation*}](https://research-vinai.monamedia.net/wp-content/ql-cache/quicklatex.com-34e5d37ed545e13aedb4240d7f7a8139_l3.svg "Rendered by QuickLaTeX.com")
the one-dimensional Wasserstein between two projected point-clouds can be solved with the time complexity  .
.
Instead of solving all optimization problems independently, an amortized model is trained to predict optimal solutions to all problems. Given a parametric function (), the amortized objective is:
(5) ![\begin{equation*} \min_{\phi \in \Phi,\gamma \in \Gamma}\max_{ \psi \in \Psi}\mathbb{E}_{X \sim p(X)}[W_p(\theta_{\psi,\gamma,\phi}\sharp P_X,\theta_{\psi,\gamma,\phi} \sharp P_{g_\gamma (f_\phi(X))})], \end{equation*}](https://research-vinai.monamedia.net/wp-content/ql-cache/quicklatex.com-799edc077188f9a8fe4d26a778f9521e_l3.svg "Rendered by QuickLaTeX.com")
where  .
.
Amortized optimization often leads to sub-optimality. Hence, it loses the metricity property since the Max-SW only obtains the identity of indiscernibles at the global optimum. Therefore, we propose to predict an entire distribution over projecting directions.
(6) 
where  ,
,  is the von Mises Fisher distribution with the mean location parameter
is the von Mises Fisher distribution with the mean location parameter  and the concentration parameter
and the concentration parameter  , and
, and
(7) 
is the von Mises-Fisher distributional sliced Wasserstein distance.
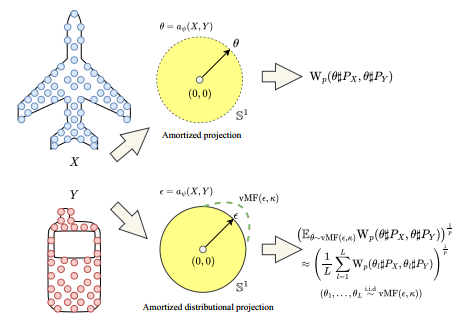
Figure 2. The difference between amortized projection optimization and amortized distributional projection optimization.
Based on the self-attention mechanism, we introduce the self-attention amortized model which is permutation invariant and symmetric. Given  , the self-attention amortized model is defined as:
, the self-attention amortized model is defined as:
(8) 
where  and
and  are matrices of size
are matrices of size  that are reshaped from the concatenated vectors
that are reshaped from the concatenated vectors  and
and  of size
of size  ,
,  is the -dimensional vector whose all entries are
is the -dimensional vector whose all entries are  , and
, and  is linear (efficient) attention module [5, 6] for preserving near-linear complexity.
is linear (efficient) attention module [5, 6] for preserving near-linear complexity.
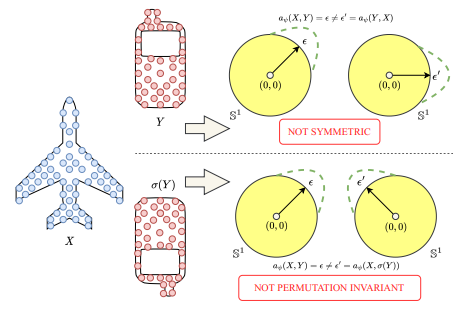
Figure 3. Visualization of an amortized model that is not symmetric and permutation invariant in two dimensions.
To verify the effectiveness of our proposal, we evaluate our methods on the point-cloud reconstruction task and its two downstream tasks including transfer learning and point-cloud generation (please see our papers for more details).
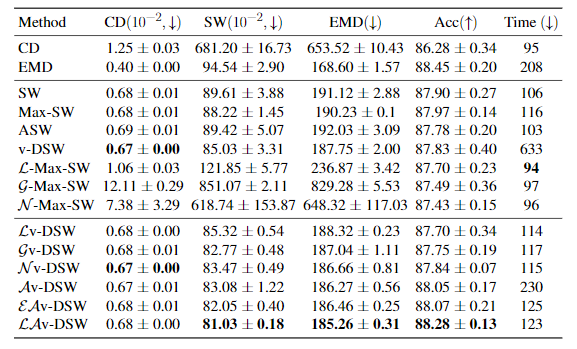
Table 1. Reconstruction and transfer learning performance on the ModelNet40 dataset. CD and SW are multiplied by 100.

Figure 4. Qualitative results of reconstructing point-clouds in the ShapeNet Core-55 dataset. From top to bottom, the point-clouds are input, SW, Max-SW, v-DSW, and  v-DSW respectively.
v-DSW respectively.
In this paper, we have proposed a self-attention amortized distributional projection optimization framework which uses a self-attention amortized model to predict the best discriminative distribution over projecting direction for each pair of probability measures. The efficient self-attention mechanism helps to inject the geometric inductive biases which are permutation invariance and symmetry into the amortized model while remaining fast computation. Furthermore, the amortized distribution projection optimization framework guarantees the metricity for all pairs of probability measures while the amortization gap still exists. On the experimental side, we compare the new proposed framework to the conventional amortized projection optimization framework and other widely-used distances in the point-cloud reconstruction application and its two downstream tasks including transfer learning and point-cloud generation to show the superior performance of the proposed framework. For further information, please refer to our work at https://proceedings.mlr.press/v202/nguyen23e/nguyen23e.pdf.
[1] Nguyen, T., Pham, Q.-H., Le, T., Pham, T., Ho, N., and Hua,B.-S. Point-set distances for learning representations of 3d point clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021.
[2] Naderializadeh, N., Comer, J., Andrews, R., Hoffmann, H., and Kolouri, S. Pooling by sliced-Wasserstein embedding. Advances in Neural Information Processing Systems, 34, 2021.
[3] Deshpande, I., Hu, Y.-T., Sun, R., Pyrros, A., Siddiqui, N., Koyejo, S., Zhao, Z., Forsyth, D., and Schwing, A. G. Max-sliced Wasserstein distance and its use for GANs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 10648–10656, 2019.
[4] Nguyen, K. and Ho, N. Amortized projection optimization for sliced Wasserstein generative models. Advances in Neural Information Processing Systems, 2022.
[5] Shen, Z., Zhang, M., Zhao, H., Yi, S., and Li, H. Efficient attention: Attention with linear complexities. In Proceedings of the IEEE/CVF winter conference on applications of computer vision, pp. 3531–3539, 2021.
[6] Wang, S., Li, B. Z., Khabsa, M., Fang, H., and Ma, H. Linformer: Self-attention with linear complexity. arXiv preprint arXiv:2006.04768, 2020.
Overall
Khai Nguyen (*), Dang Nguyen (*), Nhat Ho
Share Article

Hoang Phan, Trung Le, Trung Phung, Tuan Anh Bui, Nhat Ho, Dinh Phung

Hoang Phan, Ngoc N. Tran, Trung Le, Toan Tran, Nhat Ho, Dinh Phung

Dang Nguyen – Research Resident
