July 21, 2023
Tuan Duc Ngo, Binh-Son Hua, Khoi Nguyen
Diffusion models are rising as a powerful solution for high-fidelity image generation, which exceeds GANs in quality in many circumstances. However, their slow training and inference speed is a huge bottleneck, blocking them from being used in real-time applications. A recent DiffusionGAN method significantly decreases the models’ running time by reducing the number of sampling steps from thousands to several, but their speeds still largely lag behind the GAN counterparts. This paper aims to reduce the speed gap by proposing a novel wavelet-based diffusion scheme. We extract low-and-high frequency components from both image and feature levels via wavelet decomposition and adaptively handle these components for faster processing while maintaining good generation quality. Furthermore, we propose to use a reconstruction term, which effectively boosts the model training convergence. Experimental results on CelebA-HQ, CIFAR-10, LSUN-Church, and STL-10 datasets prove our solution is a stepping-stone to offering real-time and high-fidelity diffusion models. Our code and pre-trained checkpoints are available at https://github.com/VinAIResearch/WaveDiff.git.
This section describes our proposed Wavelet Diffusion framework. First, we present the core wavelet-based diffusion scheme for more efficient sampling. We then depict the design of a new wavelet-embedded generator for better frequency-aware image generation.

Fig 1. Illustration of Wavelet-based diffusion scheme. It performs denoising on wavelet space instead of pixel space. At each step  , a less-noisy sample
, a less-noisy sample  is generated by a denoiser
is generated by a denoiser  with parameters
with parameters  . After obtaining the clean sample
. After obtaining the clean sample  through
through  steps, it is used to reconstruct the final image via Inverse wavelet transformation (IWT).
steps, it is used to reconstruct the final image via Inverse wavelet transformation (IWT).
First, we describe how to incorporate wavelet transform in the diffusion process. We decompose the input image into four wavelet subbands and concatenate them as a single target for the denoising process (illustrated in Fig. 1). Such a model does not perform on the original image space but on the wavelet spectrum. As a result, our model can leverage high-frequency information to increase the details of generated images further. Meanwhile, the spatial area of wavelet subbands is four times smaller than the original image, so the computational complexity of the sampling process is significantly reduced.
We further incorporate wavelet information into feature space through the generator to strengthen the awareness of high-frequency components. This is beneficial to the sharpness and quality of final images.
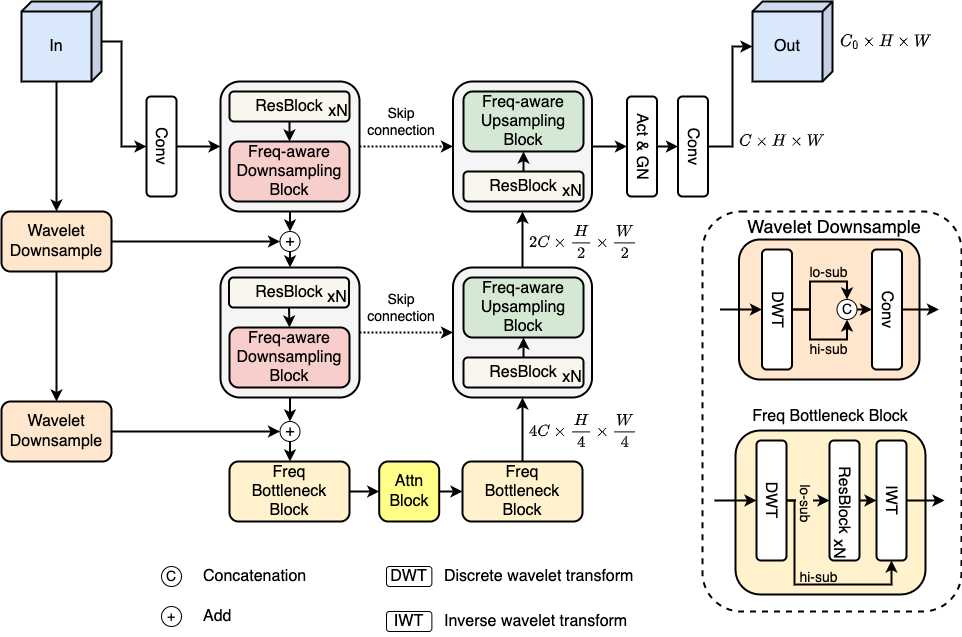
Fig 2. Illustration of Wavelet-embedded generator. For simplification, timestep embedding and latent embedding  are ignored but they are injected in individual blocks of the denoising process. The inputs are noisy wavelet subbands of shape
are ignored but they are injected in individual blocks of the denoising process. The inputs are noisy wavelet subbands of shape ![[12 \times H \times W]](https://research-vinai.monamedia.net/wp-content/ql-cache/quicklatex.com-46a1106c11e2396c9a548258c72672a8_l3.svg "Rendered by QuickLaTeX.com") at timestep , which are processed by a sequence of our proposed components, including frequency-aware upsampling and downsampling blocks, frequency residual connections, and a brand new frequency bottleneck block. The outputs of the model are the approximation of unperturbed inputs.
at timestep , which are processed by a sequence of our proposed components, including frequency-aware upsampling and downsampling blocks, frequency residual connections, and a brand new frequency bottleneck block. The outputs of the model are the approximation of unperturbed inputs.
As illustrated in the image above, it follows the UNet structure of [2] with  down-sampling and up-sampling blocks plus skip connections between blocks of the same resolution, with predefined. However, instead of using the normal downsampling and upsampling operators, we replace them with frequency-aware blocks. At the lowest resolution, we employ frequency-bottleneck blocks for better attention on low and high-frequency components. Finally, to incorporate original signals
down-sampling and up-sampling blocks plus skip connections between blocks of the same resolution, with predefined. However, instead of using the normal downsampling and upsampling operators, we replace them with frequency-aware blocks. At the lowest resolution, we employ frequency-bottleneck blocks for better attention on low and high-frequency components. Finally, to incorporate original signals  to different feature pyramids of the encoder, we introduce frequency residual connections using wavelet downsample layers.
to different feature pyramids of the encoder, we introduce frequency residual connections using wavelet downsample layers.
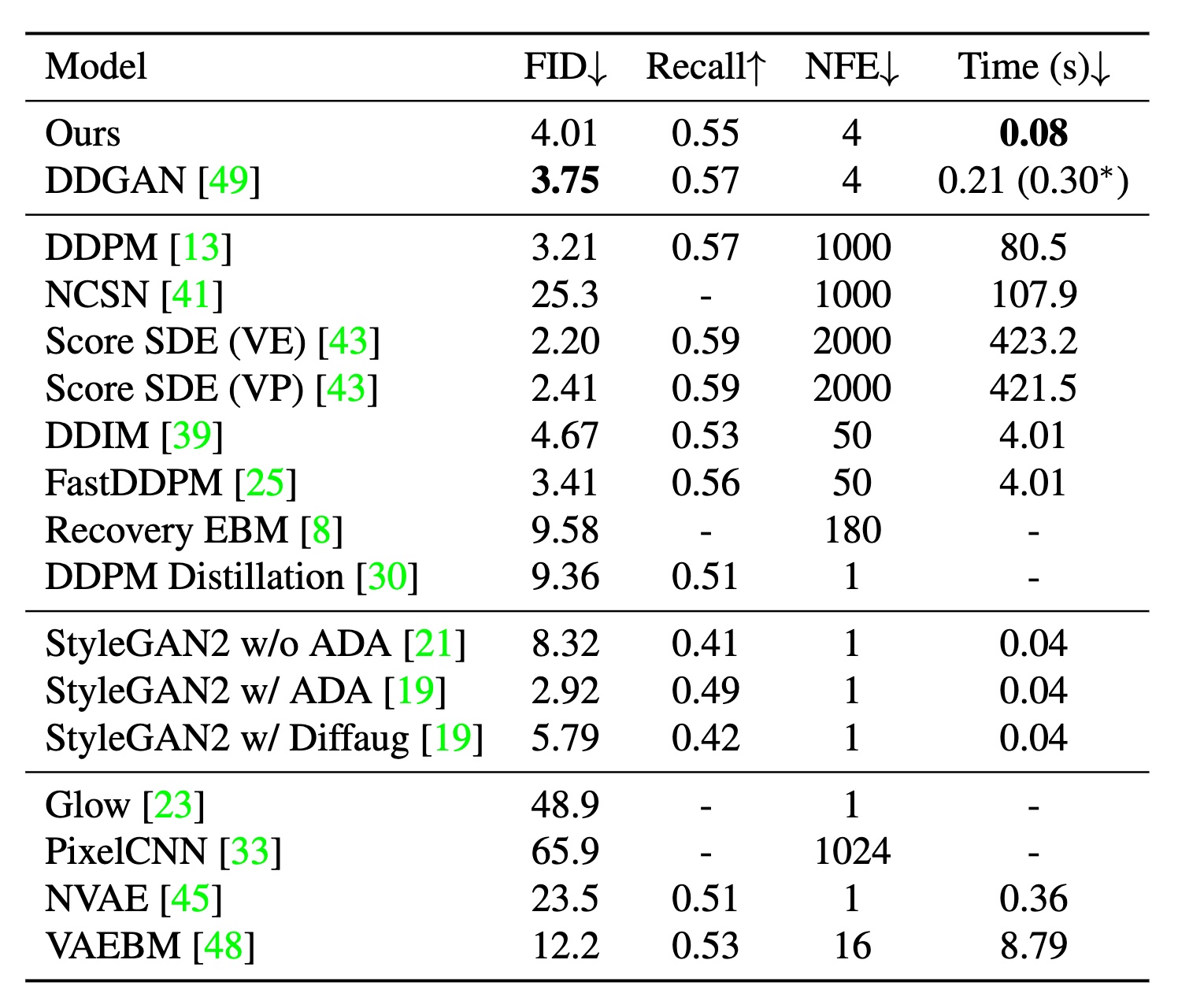
Tab 1. Results on CIFAR-10.
As shown in Tab. 1, we have greatly improved inference time by requiring only  with our wavelet-based diffusion scheme, which is
with our wavelet-based diffusion scheme, which is  faster than DDGAN. This gives us real-time performance along with StyleGAN2 methods while exceeding other diffusion models by a wide margin in terms of sampling speed.
faster than DDGAN. This gives us real-time performance along with StyleGAN2 methods while exceeding other diffusion models by a wide margin in terms of sampling speed.
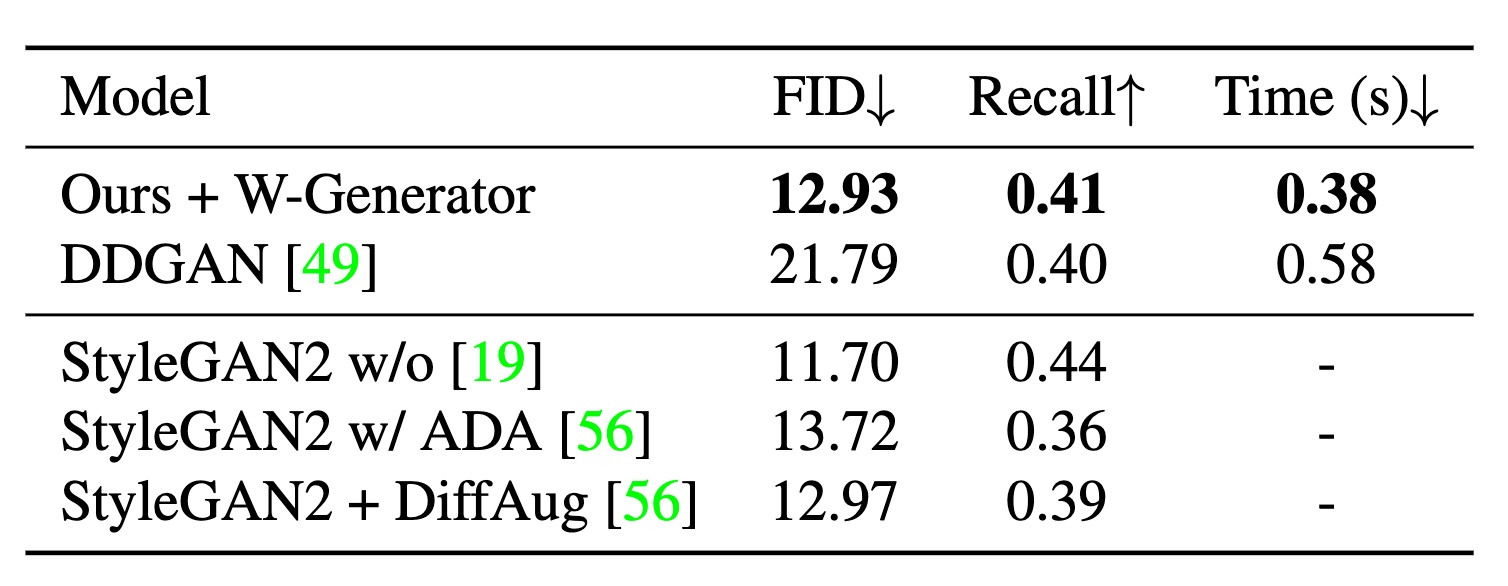
Tab 2. Results on STL-10.
In Tab. 2, we not only achieve a better FID score at  but also gain faster sampling time at
but also gain faster sampling time at  . We further analyze the convergence speed of our approach and DDGAN in Fig. 4a. Our approach offers a faster convergence than the baseline, especially in the early epochs. Generated samples of DDGAN can not recover objects’ overall shape and structure during the first 400 epochs. Besides, we provide sample images generated by our model in Fig. 4b.
. We further analyze the convergence speed of our approach and DDGAN in Fig. 4a. Our approach offers a faster convergence than the baseline, especially in the early epochs. Generated samples of DDGAN can not recover objects’ overall shape and structure during the first 400 epochs. Besides, we provide sample images generated by our model in Fig. 4b.
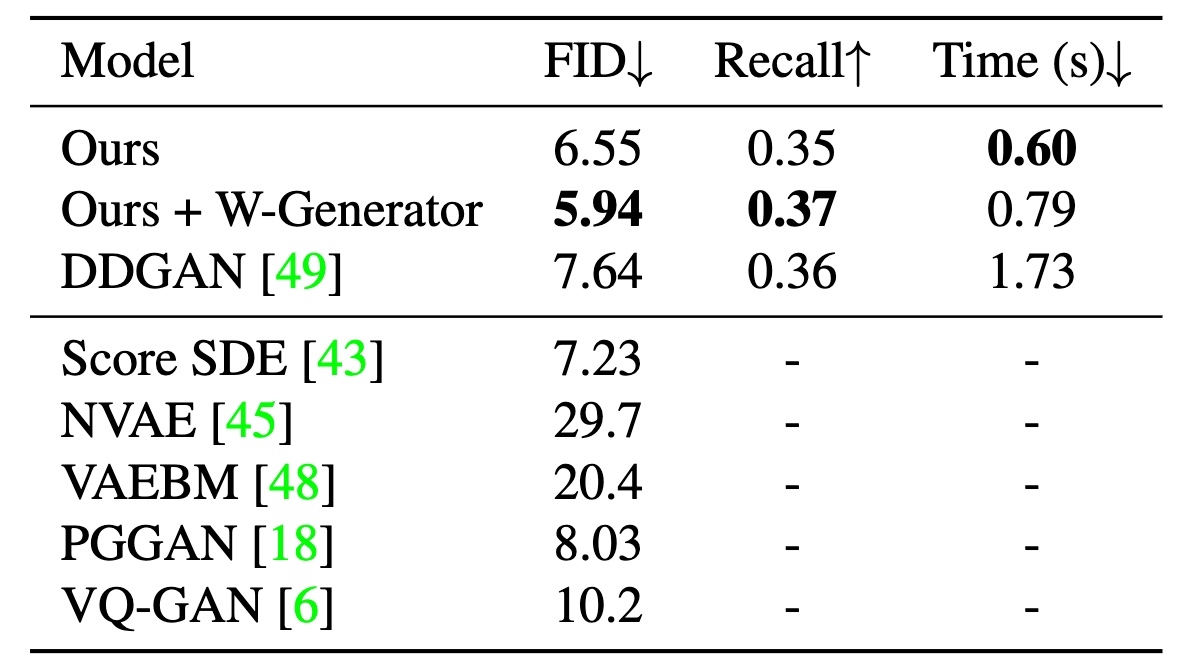
Tab 3. Results on CelebA-HQ (256 & 512).
At resolution  , we outperform some notable diffusion and GAN baselines with FID at
, we outperform some notable diffusion and GAN baselines with FID at  and Recall at
and Recall at  while achieving more than
while achieving more than  faster than DDGAN. On high-resolution CelebA-HQ (512), our model is remarkably better than the DDGAN counterpart for both image quality (
faster than DDGAN. On high-resolution CelebA-HQ (512), our model is remarkably better than the DDGAN counterpart for both image quality ( vs.
vs.  ) and sampling time (
) and sampling time ( vs.
vs.  ). We also obtain a higher recall at
). We also obtain a higher recall at  on high-resolution CelebA-HQ (512).
on high-resolution CelebA-HQ (512).
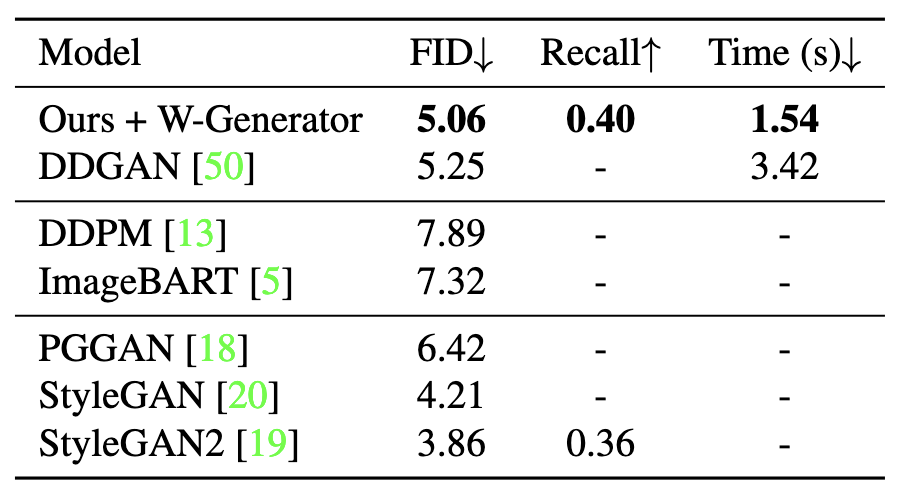
Tab 4. Results on LSUN Church.
In Tab. 4, we obtain a superior image quality at 5.06 in comparison with other diffusion models while achieving comparable results with GAN counterparts. Notably, our model offers faster inference time compared with DDGAN while exceeding StyleGAN2 [4] in terms of sample diversity at  .
.

Fig 3. Qualitative results of CIFAR-10 32 × 32
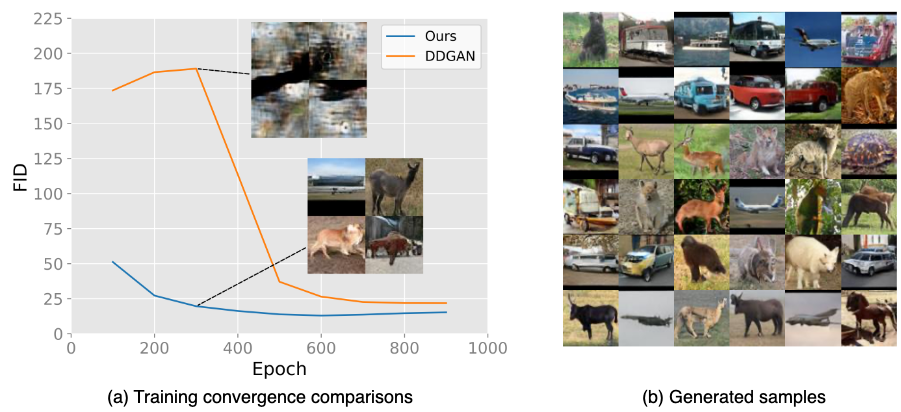
Fig 4. Training convergence comparisons (a) and qualitative results (b) on STL-10  . Our method not only converges faster but also acquires better FID scores than DDGAN [1] across different epochs.
. Our method not only converges faster but also acquires better FID scores than DDGAN [1] across different epochs.

Fig 5. Qualitative results of CelebA-HQ 256 × 256.

Fig 6. Qualitative comparison on CelebA-HQ 512. Ours produces clearer details than the baseline, such as eyebrows and wrinkles.

Fig 7. Qualitative results of LSUN Church 256 x 256.

Tab 5. Running time that it takes to generate a single sample.
We further demonstrate the superior speed of our models on single images, as expected in real-life applications. In Tab. 5, we present their time and key parameters. Our wavelet diffusion models can produce images up to  in a mere 0.1s, which is the first time for a diffusion model to achieve such almost real-time performance.
in a mere 0.1s, which is the first time for a diffusion model to achieve such almost real-time performance.
This paper introduced a novel wavelet-based diffusion scheme that demonstrates superior performance on both image fidelity and sampling speed. By incorporating wavelet transformations to both image and feature space, our method can achieve the state-of-the-art running speed for a diffusion model, closing the gap with StyleGAN models [3-5] while obtaining a comparable image generation quality to StyleGAN2 and other diffusion models. Besides, our method offers a faster convergence than the baseline DDGAN [1], confirming the efficiency of our proposed framework. With these initial results, we hope our approach can facilitate future studies on real-time and high-fidelity diffusion models.
[1] Zhisheng Xiao, Karsten Kreis, and Arash Vahdat. Tackling the generative learning trilemma with denoising diffusion gans. In ICLR, 2022.
[2] Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. In ICLR, 2021.
[3] Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. In CVPR, 2019.
[4] Tero Karras, Miika Aittala, Janne Hellsten, Samuli Laine, Jaakko Lehtinen, and Timo Aila. Training generative adversarial networks with limited data. In NeurIPS, 2020.
[5] Shengyu Zhao, Zhijian Liu, Ji Lin, Jun-Yan Zhu, and Song Han. Differentiable augmentation for data-efficient gan training. In NeurIPS, 2020.
[6] Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. In ICLR, 2021.
Overall
Hao Phung, Quan Dao, Anh Tran
Share Article

Tuan Duc Ngo, Binh-Son Hua, Khoi Nguyen

Thuan Hoang Nguyen, Thanh Van Le, Anh Tran

Tuan Ngo and Khoi Nguyen

Thanh Nguyen*, Chau Pham*, Khoi Nguyen, Minh Hoai